
在做天河部落博客系统的时候,遇到了一个这样的SQL问题,博客首页处于列表模式的时候,需要显示博主每个栏目的前十篇文章,之前是根据栏目ID一个个查询出来,由于栏目可能还有子栏目,因此使用多个栏目OR的方式,在程序里拼接好再执行,然而这些SQL语句却存在效率问题:

根据SQL Server Profiler性能工具监视可知,Duration服务执行时间很大,并且会随子栏目多少变化很大,如上10个查询总共花费了3337ms,当一个博客有几十个栏目的时候,服务器响应时间就可想而之了,几乎会感觉页面开打很慢,SQL语句如下:
select top 10 fdArtiID, fdArtiColuID, fdArtiCreateAt, fdArtiTitle, fdArtiClickCount, fdArtiReviewCount from FA_ARTICLE where fdArtiIsPub=1 and (fdArtiColuID = '633057023801718750' or
fdArtiColuID='633874888423437500' or fdArtiColuID='633372936322500000' or fdArtiColuID='633372931919531250') order by fdArtiIsTop desc, fdArtiID desc
如上栏目前十篇文章查询的Duration服务执行时间平均为217ms,而子栏目更多这个时间将更大,后面想到了另外一种方式,使用IN替换多个OR条件,SQL语句如下:
select top 10 fdArtiID, fdArtiColuID, fdArtiCreateAt, fdArtiTitle, fdArtiClickCount, fdArtiReviewCount from FA_ARTICLE where fdArtiIsPub=1 and fdArtiColuID IN ('633057023801718750','633874888423437500','633372936322500000','633372931919531250') order by fdArtiIsTop desc, fdArtiID desc
但效果仍然不明显,Duration服务执行时间差不多。查看它的执行计划,发现上面的多个IN最终还是变成多个OR来执行,而主要开销是在使用聚集索引扫描上。
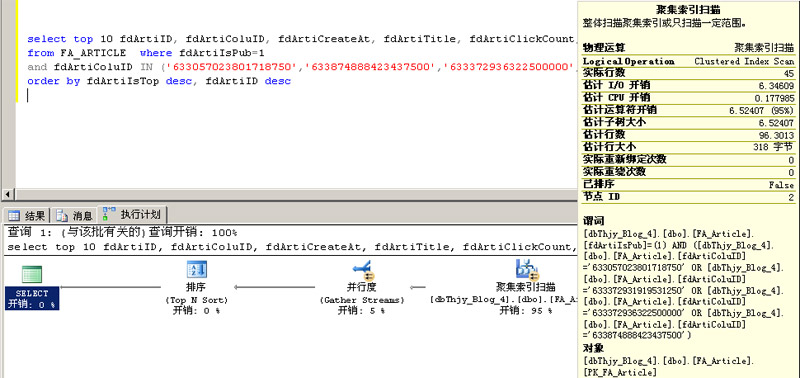
SQL Server共有4种数据查找方式:
Table Scan(表扫描):数据表上没有聚集索引,或者查询优化器没有使用索引来查找,即资料表的每一行都被检查到,如果资料表相对较小的话,表扫描可以非常快速,有时甚至快过使用索引。
Index Seek(索引查找):索引查找意味着查询优化器使用了数据表上的非聚集索引来查找数据。性能通常会很快,尤其是当只有少数的数据行被返回时。
Clustered Index Seek(聚集索引查找):这指查询优化器使用了数据表上的聚集索引来查找数据,性能很快。实际上,这是SQL Server能做的最快的索引查找类型。在创建表的PRIMARY KEY约束时,将自动创建唯一聚集索引。
Clustered Index Scan(聚集索引扫描):聚集索引扫描与表扫描相似,不同的是聚集索引扫描是在一个建有聚集索引的数据表上执行的。和一般的表扫描一样,聚集索引扫描可能表明存在效能问题。一般来说,有两种原因会引此聚集索引扫描的执行。第一个原因,相对于数据表上的整体数据行数目,可能需要获取太多的数据行。查看”预估的数据行数量(Estimated Row Count)”可以对此加以验证。第二个原因,可能是由于WHERE条件句中用到的字段选择性不高。在任何情况下,与标准的表扫描不同,聚集索引扫描并不会总是去查找数据表中的所有数据,所以聚集索引扫描一般都会比标准的表扫描要快。通常来说,要将聚集索引扫描改成聚集索引查找,你唯一能做的是重写查询语句,让语句限制性更多,从而返回更少的数据行。
由于上面是在FA_Article文章表没有栏目ID索引的情况下测试的,而文章fdArtiID是主键默认创建的是聚集索引,给栏目fdArtiColuID加一个非聚集索引后再执行:
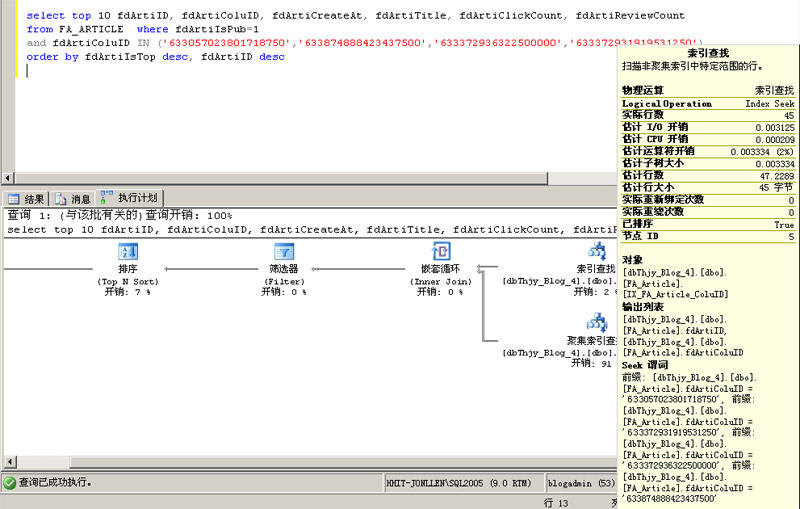
此时的查询时间终于降下来了,Duration服务执行时间约为55ms,这时候执行计划里显示使用了索引查找,即使用了非聚集索引查找数据,栏目fdArtiColuID查询方式不再是OR匹配,而是多个等于比较。55ms这个时间看上去是可以接受了,但它仍然会随子栏目多少而变化不稳定,因此还必须继续优化。
这时候出现了个小插曲,因为这时想到了个办法可以把每个栏目前10篇文章一条SQL语句一次性查询出来,这似乎是一个完美的方法,即使时间稍微长一点也没有关系,至少比每个栏目都查一次要好,一个简单的SQL如下:
select fdArtiID, fdArtiColuID, fdArtiCreateAt, fdArtiTitle, fdArtiClickCount, fdArtiReviewCount
from FA_ARTICLE AS a
where fdArtiID in
(
select top 10 fdArtiID from FA_ARTICLE
where fdArtiIsPub=1 and fdArtiColuID = a.fdArtiColuID
order by fdArtiIsTop desc, fdArtiID desc
)
AND fdArtiColuID IN ('633691599677500000','633677885317968750','633670970930156250','633371098994062500','633232866300000000','633231086737187500','633222768009687500')
单是执行上面的语句问题不大,Duration服务执行时间约为150ms,但上面我还没有列出博客所有栏目,且都是一级栏目,而栏目前十篇文章需要显示的是一级栏目或该子栏目下的文章,因此上面的子查询需要加上或者为子栏目的条件,这样才能符合需求,而在子查询里加上或者为子栏目的条件后,几乎快慢得一塌糊涂,因此最终以失败告终。后面又想到了使用临时表,但还是无果。
两三天的时间就这样摸索过了,继续回到了原点。有点无奈,无意想到了原来的旧版天河部落,听说旧版的性能很高,所以拿下来到本机借鉴参考,查看旧版读取栏目的前十篇文章的方法也是一个个分别进行查询的,但发现有个小小的差异,旧版SQL语句如下:
select top 5 fdArtiUserID, fdColuIsForum, fdArtiID, fdArtiColuID, fdArtiBlogID, fdArtiTitle, fdArtiCreateAt, fdArtiIsAuthorship, fdArtiIsHot, fdArtiIsGood,
fdArtiIsUp, fdArtiIsWorth, fdArtiClickCount, fdArtiReviewCount, fdArcgColuID, FA_Article_Column_G.fdArcgID AS Expr1
from FA_Article inner join FA_Article_Column_G
ON FA_Article_Column_G.fdArcgArtiID = FA_Article.fdArtiID
INNER JOIN FA_Column ON FA_Article_Column_G.fdArcgColuID = FA_Column.fdColuID
where fdColuBlogID = 'schqiaole' and fdColuPwd =''
and (fdColuID='632959986169218750' or fdColuParentID ='632959986169218750')
order by fdArtiCreateAt DESC
这里最大的一个差异是旧版的查询多了一个博客ID的条件,而理论上指定了栏目ID就不必要指定博客ID了,因为根据栏目ID是可以获取博客ID的,是不是加了这句就这么神奇呢?马上修改原来的SQL语句如下:
SELECT TOP 10 fdArtiID, fdArtiColuID, fdArtiCreateAt, fdArtiTitle, fdArtiClickCount, fdArtiReviewCount
FROM FA_Article
INNER JOIN FA_Column ON fdArtiColuID = fdColuID
WHERE fdArtiStatus <> 3 AND fdArtiIsPub = 1
AND fdColuUserID = 'linmeijuan'
AND (fdArtiColuID = '632788831139531250' OR fdColuParentID = '632788831139531250')
ORDER BY fdArtiIsTop DESC, fdArtiCreateAt DESC
先看一下修改后的执行计划:

再看一下没有指定博客ID条件的执行计划:

原来在没有指定博客ID的条件时查询优化器选择了哈希匹配,而加入博客ID条件后查询优化器选择了嵌套循环,fdColuUserID条件和fdColuParentID条件组合成一个嵌套循环,再和fdArtiColuID条件组合成一个嵌套循环,相当于fdColuUserID = 'linmeijuan' AND (fdArtiColuID = '632788831139531250' OR fdColuParentID = '632788831139531250')这句SQL的数据筛选。
SQL Server里有3种不同的表连接类型:
嵌套循环(Nested Loop):嵌套循环联接也称为“嵌套迭代”,它将一个联接输入用作外部输入表,将另一个联接输入用作内部输入表。外部循环逐行处理外部输入表。内部循环会针对每个外部行执行,在内部输入表中搜索匹配行。如果外部输入较小而内部输入较大且预先创建了索引,则嵌套循环联接尤其有效。一般来说,索引嵌套循环联接优于合并联接和哈希联接。但在大型查询中,嵌套循环联接通常不是最佳选择。
散列(Hash):哈希联接用于多种设置匹配操作:内部联接;左外部联接、右外部联接和完全外部联接;左半联接和右半联接;交集;联合和差异。哈希联接按不同类型又分为内存中的哈希联接、Grace 哈希联接和递归哈希联接。
合并(Merge):合并联接要求两个输入都在合并列上排序,而合并列由联接谓词的等效 (ON) 子句定义。合并联接本身的速度很快,但如果需要排序操作,选择合并联接就会非常费时。然而,如果数据量很大且能够从现有 B 树索引中获得预排序的所需数据,则合并联接通常是最快的可用联接算法。
总结
在我们平时SQL性能优化中,需要结合实际需求,使用好执行计划(Query Execution Plan)和事件探察器(SQL Server Profiler)两大利器,而不是一概的说不要使用OR、IN,自己去测试实践的结果才是最好的证明。
参考资料:
- 引用
1楼 三维网 2010-08-17 14:37:03